Improving Azure Cosmos DB efficiency
, by Catalin Gavan
When using Azure Cosmos DB, you quickly realize how fast Request Units (RUs) are consumed and how easily the costs can add up.
Inefficient queries don't just impact application performance, but they can also significantly increase the monthly Azure bill.
While refactoring the Azure integration for Logbee, I tested a few optimization techniques that helped reduce the RU consumption by a steady 75%, all without sacrificing performance - if anything, it actually improved.
Here are the most important discoveries:
1. Index only the properties used in queries
Indexing is one of the most expensive operations performed by Cosmos DB.
By default, when inserting a new document, Azure will index every single property of the document. The more (nested) properties a document has, the more indexing overhead will incur on every insert, update or upsert operation.
The default indexing policy looks something like this:
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/\"_etag\"/?"
}
],
"fullTextIndexes": []
}
Instead of using the default indexing policy, I configured the containers to exclude everything by default and explicitly index only the fields that are used in queries, either as filter or as sort keys.
For example, Logbee stores the HTTP request logs in a container called RequestLog. Each document includes many fields, including:
- startedAt
- duration
- request.method
- request.url
- request.userAgent
- response.contentLength
- response.statusCode
But since the UI doesn't support filtering or sorting by request.userAgent or by response.contentLength, there is no need to index them.
Following this principle, I configured the Cosmos DB container to index only the necessary fields and exclude everything else.
The new indexing policy for the RequestLog container looks like this:
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/partitionKey/?"
},
{
"path": "/startedAt/?"
},
{
"path": "/response/statusCode/?"
},
{
"path": "/request/url/path/?"
}
],
"excludedPaths": [
{
"path": "/*"
},
{
"path": "/\"_etag\"/?"
}
],
"fullTextIndexes": []
}
NOTE: When using an "exclude-all" strategy, you must explicitly include the partition key, as it will not be indexed anymore by default.
The result?
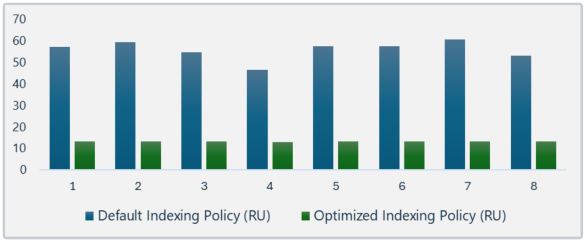
I compared RU usage for 8 identical insert operations on two containers:
- One using the default indexing policy
- One using the optimized policy
| Default Indexing Policy (RU) | Optimized Indexing Policy (RU) | Improvement |
|---|---|---|
| 57.14 | 13.14 | 77.0% |
| 59.24 | 13.14 | 77.8% |
| 54.67 | 13.14 | 76.0% |
| 46.38 | 12.86 | 72.3% |
| 57.33 | 13.14 | 77.1% |
| 57.33 | 13.14 | 77.1% |
| 60.50 | 13.14 | 78.3% |
| 52.90 | 13.14 | 75.2% |
That's almost a 76% improvement for every insert operation!
And since approximately 90% of Logbee's Cosmos DB operations are inserts, the overall savings really adds up.
2. Use Blob storage to reduce the size of Cosmos DB documents
Large documents in Cosmos DB consume more Request Units (RUs), not just during inserts but also when they are queried or read.
If your application is storing large documents, reducing their size will have a beneficial impact for the performance improvements and cost savings.
The approach
Continuing with the RequestLog container example from earlier, a sample document would look like this:
{
"id": "da30271b-faf2-4b09-b34f-e7da7c03b397",
"partitionKey": "1786d2e5-669b-439b-9c30-8f5decfb396e",
"startDateTime": "2025-04-04T12:26:56.7191394Z",
"durationInMilliseconds": 125,
"request": {
"userAgent": "Mozilla/5.0 ...",
"method": "GET",
"url": {
"path": "/cart/checkout"
},
"headers": [
{ "key": "Accept", "value": "*/*" },
{ "key": "Connection", "value": "keep-alive" }
]
},
"response": {
"statusCode": 200,
"contentLength": 1937,
"headers": [
{ "key": "Content-Type", "value": "text/html" },
{ "key": "Content-Length", "value": "1937" }
]
},
"logs": [
{ "level": "Information", "message": "Successfully validated the token." },
{ "level": "Warning", "message": "Shopping cart could not be fetched from cache" }
],
"exceptions": [
{ "type": "System.TimeoutException", "message": "The operation has timed out" }
]
}
While all these properties are relevant, not all of them are visible in the list-view when displaying the requests in the UI.
Storing all these hidden fields - that are not visible in the list-view, nor they are used in queries, is redundant.
So, I created a simplified document that look like this:
{
"id": "da30271b-faf2-4b09-b34f-e7da7c03b397",
"partitionKey": "1786d2e5-669b-439b-9c30-8f5decfb396e",
"startDateTime": "2025-04-04T12:26:56.7191394Z",
"durationInMilliseconds": 125,
"request": {
"method": "GET",
"url": {
"path": "/cart/checkout"
}
},
"response": {
"statusCode": 200,
"contentLength": 1937
},
"numberOfLogs": 2,
"numberOfExceptions": 1,
"blobName": "RequestLogs/application:1786d2e5-669b-439b-9c30-8f5decfb396e/id:da30271b-faf2-4b09-b34f-e7da7c03b397.json"
}
Fields like userAgent, headers and the full logs array are excluded, since they are neither visible in the UI list view nor used in queries.
I have created summary fields like numberOfLogs and numberOfExceptions, which can support both filtering and sorting.
What about the removed data?
While I am now saving a lightweight version of the document in Cosmos DB, I store the full payload equivalent in Azure Blob Storage.
When I need to display the details of a request (such as when opening the request modal), I load the payload from Azure Blob Storage.
This way, the Cosmos DB document stays lightweight while still having access to the full details when needed.
Azure Blob Storage also supports automatic cleanup policies, so I don't have to worry about storage growing too much.
The result?
Retrieving 200 documents from the simplified container shows major gains:
| Metric | Full document | Simplified document | Improvement |
|---|---|---|---|
| Request Charge | 26.24 RUs | 9.51 RUs | 64% |
| Retrieved Document Size | 942,218 bytes (~942 KB) | 141,329 bytes | 85% |
| Output Document Size | 1,229,278 bytes (~1.2 MB) | 215,031 bytes | 82% |
| Document Load Time | 5.83 ms | 1.53 ms | 74% |
| Query Engine Time | 0.53 ms | 0.25 ms | 53% |
| Document Write Time | 6.53 ms | 1.34 ms | 80% |
3. Enable Time to Live (TTL)
This one might already be obvious, but it can be easy to overlook.
If your application stores temporary or time-sensitive data (such as logs, telemetry, session info, cache data), enabling Time to Live (TTL) ensures outdated documents are deleted automatically.
It is a simple setting that helps keep your containers clean and your storage costs under control, without the need of custom cleanup logic.
More details about the TTL can be found on Microsoft Docs.
Wrapping up
A final recommendation is setting EnableContentResponseOnWrite=false when performing insert/update operations.
This prevents Cosmos DB from returning the document content after every write operation, which I never found the need for until now.
Optimizing Cosmos DB performance results in immediate and noticeable improvements in both cost-efficiency and speed.
If you are dealing with high write volumes or large datasets, even small tweaks like indexing and document size can have a massive cumulative impact.